

Cette semaine, le web a été marqué par un bras de fer juridique sur la propriété des données, des innovations Google qui redéfinissent l’analyse du SEO, et de nouvelles études sur l’impact réel de l’IA sur la visibilité en ligne.
- Reddit vs SerpAPI : la bataille juridique autour de la propriété et de la liberté des données web continue.
- Query Groups : la Google Search Console regroupe désormais les requêtes par intention de recherche (fonctionnalité en test pour les gros sites).
- IA & SEO : 90 % des entreprises craignent de perdre leur visibilité SEO face à l’IA.
- ChatGPT : 67 % des sources citées par le modèle IA sont inaccessibles aux marques selon Ahrefs.
- Claude (Anthropic) : les chercheurs dévoilent comment les LLM “perçoivent” la structure du texte, et comment mieux rédiger pour les IA.
- Chrome : les sites encore en HTTP à partir de 2026 verront une alerte s’afficher pour tous les utilisateurs avant le chargement de la page.
- Google Discover : décryptage du fonctionnement interne de l’algorithme et de ses leviers SEO.
Bonne lecture !
(ok j’ai triché, je n’ai pas publié vendredi comme j’aurais préféré le faire, mais j’ai eu BEAUCOUP d’incendies à éteindre côté client)
Table des matières
Procès Reddit : une menace pour l’internet libre selon SerpAPI
Accusé par Reddit d’avoir utilisé les données de sa plateforme sans consentement, SerpAPI répond à l’attaque en justice en déclarant que les données de recherche mises à disposition du public devraient rester libres d’accès à tous. Le crawler, ainsi que 3 autres acteurs (dont Perplexity) sont accusés de collecter et de revendre des données en utilisant les résultats de Google.
Un peu de contexte : Reddit a un contrat d’exclusivité sur ses données avec OpenAI et un autre avec Google.
Pourquoi c’est important ? Ce procès n’est pas juste à propos de la protection des données, mais de contrôle de l’information. Les entreprises tech se battent pour savoir qui possède la donnée à la base des résultats de recherche et des réponses générées par IA. Pendant ce temps, les marques tentent de comprendre ce qui influence la visibilité, le positionnement et l’attribution.
- SerpAPI calls Reddit lawsuit a threat to the ‘free and open web’ Source : Search Engine Journal
Google introduit les Query groups dans Search Console Insights
Lundi 27 octobre, Google a annoncé l’arrivée des groupes de requêtes sur la Google Search Console, une fonctionnalité à retrouver dans l’onglet Insights qui regroupe les requêtes de recherche similaires. Objectif : regrouper en un seul groupe les requêtes distinctes qui reflètent une intention de recherche similaire, et éviter de multiplier de nous faire créer des contenus trop proches.
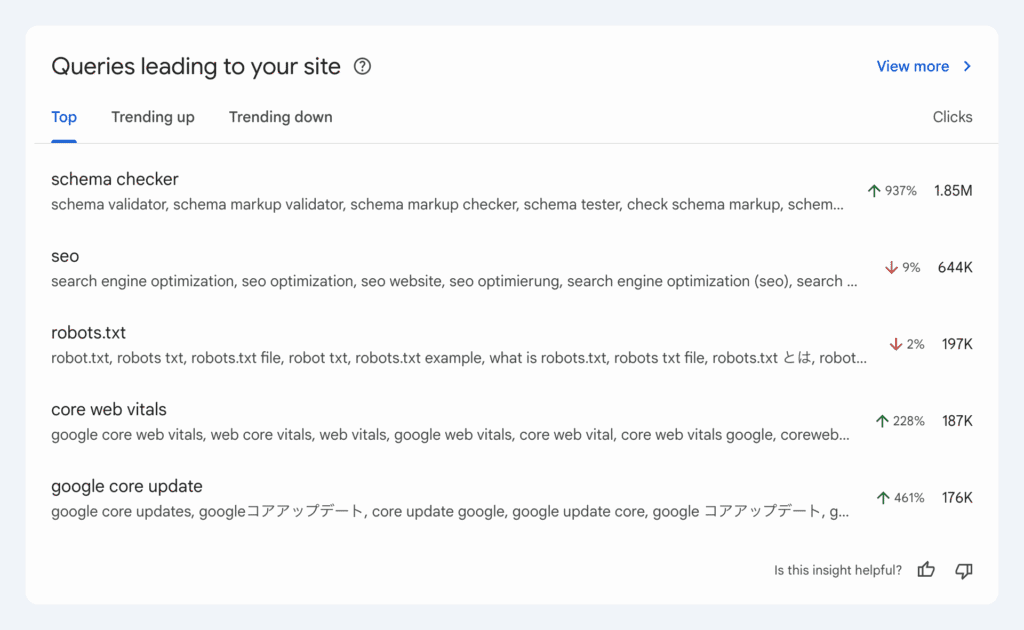
Si on se réfère au screenshot ci-dessus, l’affichage classique de la Search Console aurait affiché de manière séparée les mots-clés schema validator”, “schema markup validator”, “check schema markup”, etc.
On voit également que les requêtes plus techniques orientées performance de site (Core Web Vitals, Google Core Update…) explosent, alors que les requêtes génériques liées au “SEO” stagnent ou diminuent. Les gens ne cherchent plus simplement “SEO”, mais “comment améliorer mes Core Web Vitals”, “impact du core update”, etc. Cela confirme une maturité du marché : les utilisateurs cherchent désormais des solutions précises, et non pas pas des définitions globales.
“Makes it easier to track how things are changing (or not) for a group of similar queries from traditional search, AI Overviews, and AI Mode.”
John Mueller sur Bluesky
Après, le bon John nous dit ça, on n’a pour le moment aucune visibilité sur les AI Overviews et le Google AI Mode depuis la Search Console…
Attention : Google précise que ces regroupements sont calculés via des modèles d’IA susceptibles de changer au fil du temps, en fonction des évolutions du langage et des comportements de recherche. Les Query groups sont en cours de déploiement progressif dans le rapport Search Console Insights. Seules les propriétés enregistrant un volume significatif de requêtes y auront accès, car le regroupement n’aurait que peu d’intérêt sur des sites à trafic limité.
- Présentation des groupes de requêtes dans Search Console Insights Source : Google Search Central Blog
- Google Search Console adds Query groups Source : Search Engine Land
- Query Groups Report Comes To Google Search Console Insights Source : Siècle Digital
- Google introduit les Query groups dans Search Console Insights : une nouvelle façon d’analyser vos requêtes de recherche Source : Abondance
- Google Search Console permet de suivre des groupes de requêtes autour d’une même intention Source : Blog du Modérateur
90% des entreprises ont peur de perdre leur visibilité naturelle à cause de l’IA
Les marques n’ont pas attendu que l’IA générative supplante le SEO pour agir : plus de 85% ont déjà investi dans le GEO, et 61% envisagent d’améliorer les bases de leur SEO. La raison : 9 entreprises sur 10 ont peur de perdre des clients potentiels.
Pourquoi c’est important ? Le basculement des résultats de recherche aux réponses générées par IA semblent intervenir plus vite que ne l’avaient anticipé bon nombre de business. En réponse à cette crainte, les marques se voient obligées de revoir leur copie. L’IA modifie le parcours utilisateur tel que nous le connaissions et force le SEO classique à évoluer.
“J’ai peur qu’on ne trouve plus mon business en ligne”
La première crainte des 300+ entreprises interrogées dans le sondage
L’espoir est cependant permis : plusieurs études suggèrent que le trafic issu de ChatGPT et des autres LLM convertit moins bien que les recherches Google.
- SEO for AI (GEO) Statistics: 90% of Businesses Are Worried About the Future of SEO and Organic Findability Due to AI / LLMs Source : Smarty Marketing
- 90% of businesses fear losing SEO visibility as AI reshapes search Source : Search Engine Land
67% des sources citées par ChatGPT ne pourront jamais être exploitées par les marques
Sur le site d’Ahrefs, Louise Linehan a analysé les 1 000 pages web les plus citées par ChatGPT (en septembre 2025), à l’aide de l’outil Brand Radar d’Ahrefs. Objectif : comprendre quels types de contenus ChatGPT cite le plus souvent et dans quelle mesure ces sources peuvent être influencées ou exploitées par les marques.
ChatGPT cite majoritairement des pages “inaccessibles”. 2/3 des sources citées par le modèle d’IA sont des pages qu’on ne peut pas faire modifier pour ajouter des backlinks ou du contenu qui relie vers notre propre site. Ces sources proviennent de pages Wikipédia (29,7%), de homepages ou Landing Pages d’autres marques…
Quels contenus modifier pour être cité par l’IA ? Le tiers de contenus “influençables” sont les contenus éducatifs (généralement chez d’autres marques), les avis en lignes, les articles de news, et les articles de blog. Prendre contact avec ces sources pourrait permettre d’apparaître plus souvent dans les réponses de ChatGPT. Après, je rappelle que les modèles d’IA ne partagent pas les mêmes sources.
28% des pages les plus citées par ChatGPT n’ont aucun trafic organique. Près d’un tiers des pages citées par ChatGPT ne rankent pas du tout dans Google, et n’ont aucun mot-clé organique ni trafic SEO. Cela montre que ChatGPT ne se base pas sur le référencement naturel pour choisir ses sources. Soit il prend du contenu très frais qui n’a pas ou peu été indexé, soit il s’agit de sujets de niche, soit les critères de sélextion de ChatGPT diffèrent de ceux de Google. En théorique, un article sans visibilité SEO peut être cité des milliers de fois par ChatGPT, simplement parce qu’il correspond parfaitement à une question fréquente dans ses conversations.

Pour être cité par l’IA, vous devez travailler votre SEO. 65% des pages citées par ChatGPT on un DR > 80, rankent pour un nombre médian de 279 mots-clés et sont positionnés en Top3 de Google pour au moins 1 mot-clé. La seule exception semble être l’hyper-pertinence de certaines requêtes. En clair : ChatGPT cite surtout des pages issues de sites très puissants (Wikipedia, médias, sites officiels, etc.), mais pas forcément leurs pages les plus populaires.
Ce que vous devez faire niveau SEO et Marketing Digital pour être cité par l’IA. Créez des contenus éducatifs et explicatifs, même s’ils sont hyper-niche. Le but est d’apporter de l’information à votre audience et de lui être utile. N’hésitez pas à identifier les blogs d’autorité et les média qui publient dans votre niche pour obtenir des backlinks. Et mettez à jour votre contenu : les LLM adorent le contenu frais.
- 67% of ChatGPT’s Top 1,000 Citations Are Off-Limits to Marketers (+ More Findings) Source : Ahrefs
- The 50 Best PR Pitching Opportunities in ChatGPT Source : Ahrefs
Comment les LLM interprètent votre contenu ?
Anthropic, l’entreprise derrière le modèle LLM Claude, a analysé comment les grands modèles de langage “perçoivent” le texte qu’ils génèrent. Objectif : comprendre comment un modèle IA sait où couper une ligne de texte pour qu’elle tienne dans une largeur donnée.

Le défi du retour à la ligne pour l’IA générative. Imaginez que vous demandez à votre modèle d’IA de vous aider à écrire un texte qui a une structure assez fixe comme un poème ou une chanson. Pour savoir ce qu’il doit générer, le modèle d’IA doit compter le nombre de caractères déjà écrit, évaluer la place restante, évaluer si le prochain mot probable tient dans le contenu, ou passer à la ligne suivante. C’est un comportement proche de la réflexion humaine : il doit réfléchir à ce qu’il écrit, planifier ses prochains mots et se rappeler ce qu’il a déjà écrit.
Claude voit le texte généré comme une barre de progression. Au lieu de voir une suite de symboles, le modèle d’IA comprend la ligne de texte comme un espace dans lequel il se déplace progressivement. Il garde en tête une sorte de limite mentale pour savoir quand retourner à la ligne. Il va constamment se pose la question de savoir s’il doit continuer la phrase ou commencer sur une autre, un peu comme un humain perçoit le bord d’une feuille de papier lorsqu’il écrit à la main.
En quoi cette découverte est intéressante pour le SEO ou le marketing ? Concrètement cette découverte ne va pas révolutionner votre manière d’écrire de meilleurs contenus optimisés pour le SEO. Par contre cela signifie que si vous demandez à un LLM de vous générer un texte sur un sujet donné, il va lui manquer énormément d’élément. Même si vous lui donnez des contenus pour orienter sa réflexion et cadrer le texte généré par IA, le modèle ne saura pas si le contenu que vous lui fournissez est vrai ou faux, quelle est l’intention de recherche derrière, ni même quelle information est plus importante qu’une autre. En clair, tous ces éléments nécessitent un oeil humain.
Pourquoi la structure de vos textes importent pour être cité par l’IA ? Si on extrapole un peu, la recherche indique que l’IA “ressent” les transitions d’une partie à l’autre d’un texte. Donc une structure claire (titres, paragraphes courts, transitions nettes, etc.) aide les modèles d’IA à mieux percevoir et résumer le contenu d’un article de blog. Lorsqu’on passe d’une idée ç une autre, il faut être explicite, via l’utilisation de sous-titres ou de connecteurs logiques : donc, par conséquent, finalement…
- When Models Manipulate Manifolds: The Geometry of a Counting Task Source : Transformer Circuits
- Anthropic Research Shows How LLMs Perceive Text Source : Search Engine Journal
Votre site répond toujours en HTTP ? Google Chrome émettra une alerte à partir de 2026
A partir de 2026, dès que vous vous connecterez à un site qui répond en HTTP, le navigateur Google Chrome alertera les utilisateurs avant de se connecter au site à partir d’octobre 2026. Les sites privés comme les adresses IP locales et les pages d’intranet seont exclues de cette alerte.

Ce que ça signifie si votre site est toujours en HTTP. Google Chrome activera par défaut une nouvelle option appelée “Always Use Secure Connections” (Toujours utiliser une connexion sécurisée) qui affichera un message d’avertissement avant que l’utilisateur puisse y accéder. Le message sera bypassable (contournable), mais il indiquera que la connexion n’est pas sécurisée.
Selon Google : 97 à 99 % des sites publics utilisent déjà HTTPS. Le petit pourcentage restant représente encore des millions de visites non sécurisées chaque jour. En effet, un hacker pourrait intercepter ou modifier les données entre le navigateur et le serveur.
Les risques pour votre SEO. Si votre site est encore en HTTP, beaucoup d’internautes feront demi-tour avant-même le chargement du site web. Ce comportement fera baisser ton taux de clics (CTR) depuis Google, qui l’interprétera comme un signal négatif de comportement utilisateur. En plus de la perte de visibilité à court terme, vous risquez de perdre votre positionnement SEO. En pratique, les sites HTTP deviendront quasiment inaccessibles via Google Search.
Ce que vous devez faire dès maintenant. Vérifiez votre certificat SSL, et redirigez toutes les URL qui répondent en HTTP vers leur version en HTTPS (vos liens internes et les backlinks qui pointent vers votre site).
- Chrome To Warn Users Before Loading HTTP Sites Starting Next Year Source : Search Engine Journal
Savez-vous comment fonctionne réellement Google Discover ?

Harry Clarkson-Bennett (SEO Director au Telegraph), s’’appuie sur’est appuyé sur le dernier Google Leak pour casser la boîte noire qu’est Google Discover, le fil d’actualités personnalisé que Google pousse sur mobile. Selon lui, Discover fonctionne via un pipeline en 6 étapes, un peu comme une chaîne de production de contenu :
- Éligibilité et filtrage : votre site doit être considéré comme fiable par Google en fonction de l’autorité du site, la pertinence thématique, et la réputation de l’auteur. Pas de confiance = pas de Google Discover.
- Exposition initiale et test : Google teste ton attractivité avec un ou deux contenus d’actualité. Si l’article attire des clics rapidement, il passe à l’étape suivante. D’où un travail sur le copywriting des titres pour attirer des clics.
- Évaluation de la qualité par les utilisateurs : Google analyse le taux de clic, le temps passé sur la page, le nombre d’interactions, etc. Ces signaux proviennent de Discover, de Chrome, des réseaux sociaux et des autres canaux qui redirigent vers ce contenu. Des clics rapides + un bon engagement = un signal fort de satisfaction utilisateur.
- Boucle d’engagement et réévaluation : Discover évalue ton contenu en permanence. Tant qu’ilreste performant, il sera poussé sur le fil d’actualité, sinon, il sera remplacé par d’autres articles plus engageants.
- Personnalisation : Discover ajuste le fil d’actualité des internautes en fonction de leurs centres d’intérêts (perçus sur les autres produits Google), tes interactions précédentes dans Discover et ta cohorte (groupe d’utilisateurs aux goûts similaires). Chaque article affiché est choisi en fonction de ton comportement et de ceux qui te ressemblent.
- Décroissance et renouvellement : Les articles dans Discover ont une durée de vie courte. Tout comme sur les réseaux sociaux, il faut constamment publier du contenu frais.
Pourquoi c’est important ? Google Discover est une source majeure de trafic pour les médias, blogs et sites d’actualité. Il pourrait devenir un levier SEO majeur en 2026. On entre dans une ère où Google pousse le contenu autant qu’il le classe. our les marques et les éditeurs, cela signifie qu’il faut renforcer son autorité thématique, publier du contenu engageant et clair, et stimuler les signaux positifs dès la mise en ligne via les réseaux ou les newsletters. En SEO, Discover marque une évolution vers un modèle plus éditorial et comportemental, où la pertinence et la satisfaction priment sur la simple optimisation technique.
- How Google Discover REALLY Works Source : Search Engine Journal
Retrouvez aussi mes dernières publications sur le LinkedIn de @Plume Numérique et de @Sandrine Lasserre
Les articles publiés cette semaine sur le blog de Plume Numérique
Voir tous les articles du blog


0 commentaires